测试的环境:Goodle AI Studio
测试的模型:选择Gemini 2.5 Pro Experimental 03-25
测试形式:通过向模型发送指令(prompt)
测试一:让此模型使用HTML CSS和JavaScript构建一个响应式Web应用程序,使用户能够跟踪他们的每月收入和支出。(评估模型的数学能力)
将此模型输出的三个文件放入Vs Code,注意三个文件要在同一个文件下。
完成后我们打开HTML文件可以看到
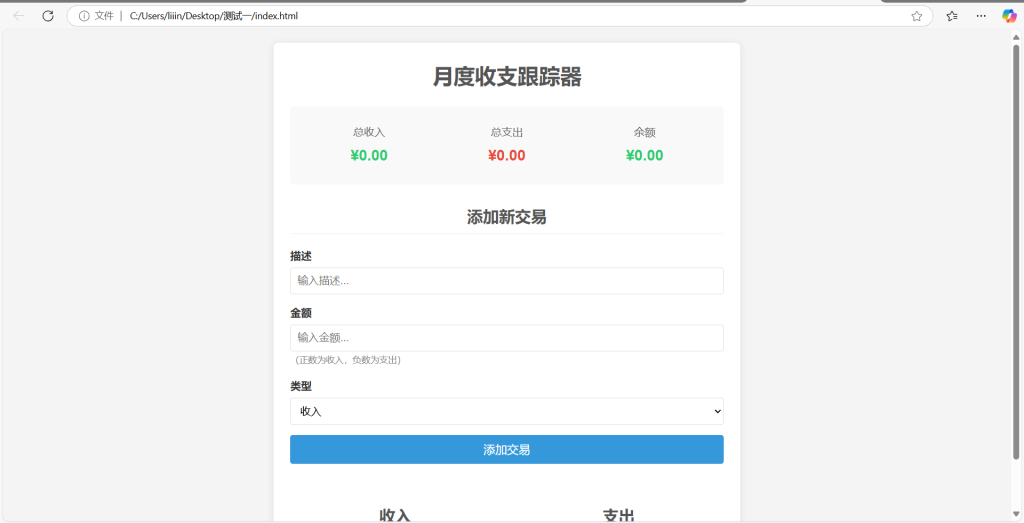
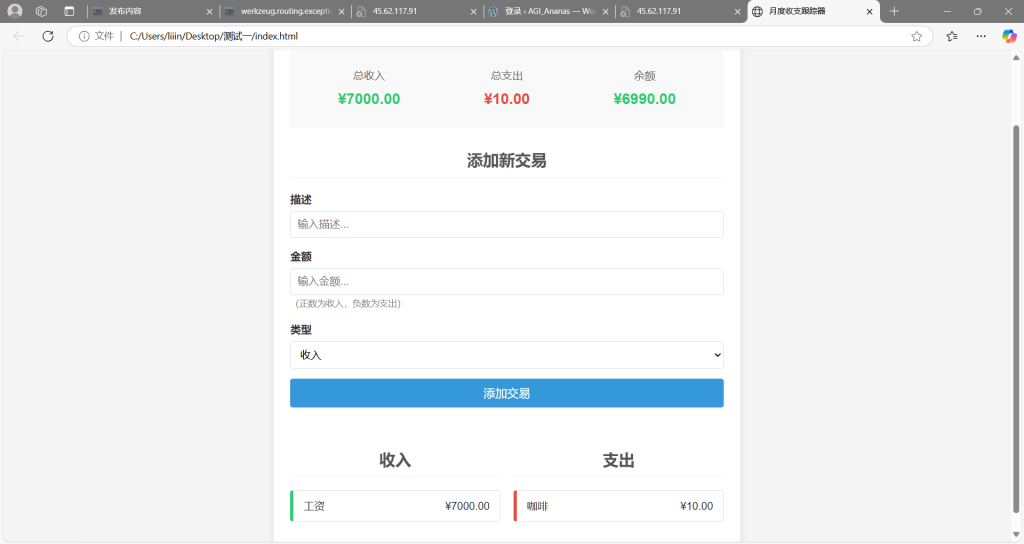
操作结果:操作通过。用户可以自由添加支出收入金额,添加相应描述,同时系统会统计总支出,总收入和余额。
测试二:创建一个生命游戏(Conway The Game Of Life)(评估模型的逻辑能力)
康威生命游戏是什么:

操作过程:向模型发出指令,但这次我们选择在python脚本中运行。
操作结果:测试通过,生成康威生命游戏
测试三:发送一个任何模型都难以解决的问题——利用SVG语法创建一个对称翅膀和简单造型的蝴蝶。(评估模型输出SVG代码的能力)
操作过程:向模型发出指令,并将SVG 代码输入在线工具中来查看。
操作结果:测试通过,利用svg语法生成蝴蝶。
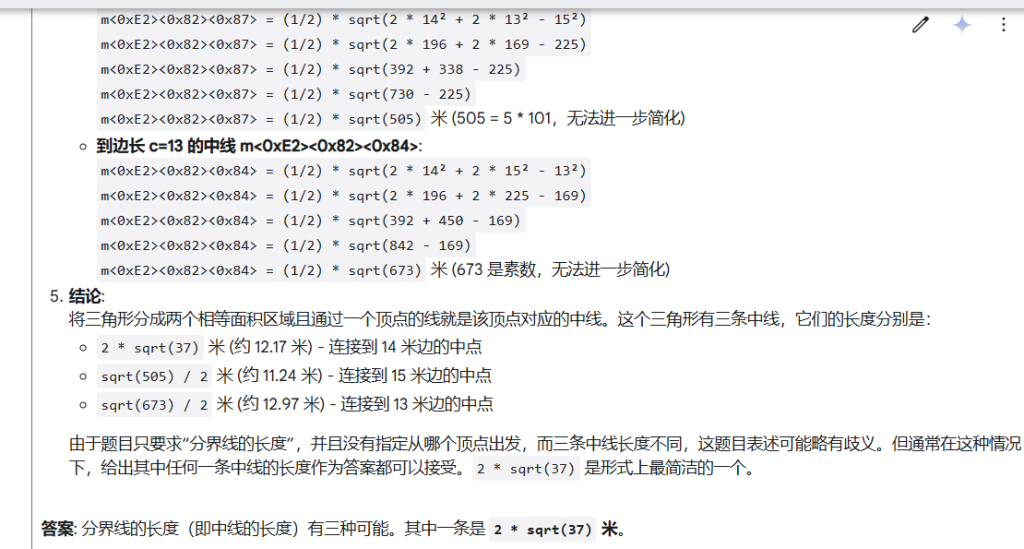
测试四:一个农民有一块三角形的天地,它的边不同,有三种不同的长度。13米,14米,15米。他想用一条通过其中一个顶点的线将它分成两个面积相等的区域,求出分界线的长度。(测试数学几何)
测试结果:通过。
测试五:一列火车在早上8点从A市出发以每小时70公里的恒定速度驶向500公里外的B市,火车B于上午9点从B市出发以每小时80公里的恒定速度驶向A市,火车A 在出发两小时后每隔15分钟停靠一次,火车B不间断行驶。两列火车在什么时间相遇?火车在离A市多远的地方实际相遇?(测试模型的代数和速率)
测试结果:通过。
模型进行了这几个步骤:分析初始阶段 (8:00 AM – 9:00 AM)——分析第二阶段 (9:00 AM – 10:00 AM)——分析第三阶段 (10:00 AM 之后)——计算相遇时间——计算相遇地点 (距离A市)

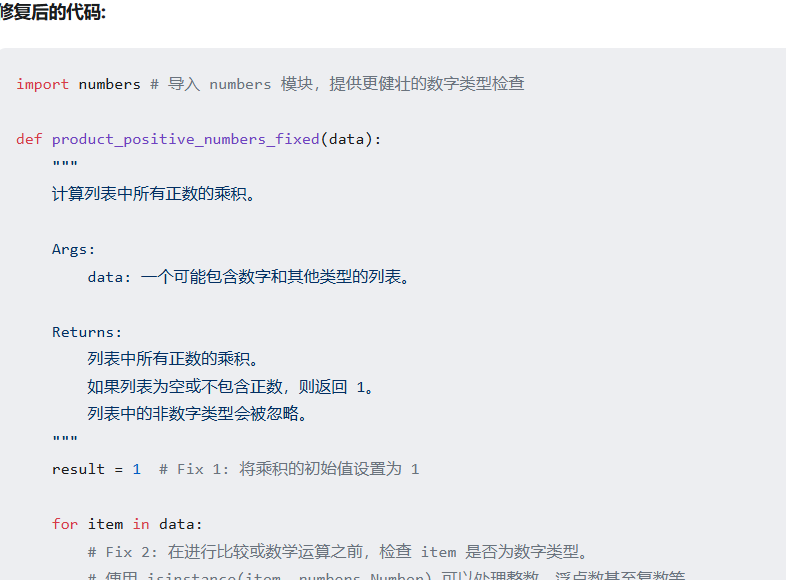
测试六:识别修复pythonPython 函数中的逻辑错误和潜在的运行时错误。该函数旨在返回所有正数的乘积。如果列表不包含正数,则应返回 1。该函数还应通过忽略非数字类型的列表来妥善处理它们。(三处错误)

测试结果:通过

测试七:图书馆需要购买总计正好 250 美元的教学材料。他们可以以每本 12 美元的价格购买练习册,以每本 35 美元的价格购买教育应用程序许可证,以每本 55 美元的价格购买科学套件。他们必须购买每种类型的物品中的至少一个。找出满足这些条件的所有可能组合(练习册、应用程序、套件的数量)。(测试离散数学中的数论,线性方程)
测试结果:通过

测试八:一个城镇有两种人:说真话的人(总是说真话)和撒谎的人(总是撒谎)。你遇到了三个人:A、B 和 C。A 说:“B 是个撒谎者。”B 说:“C 是个说真话的人。”C 说:“A 和 B 属于不同类型。”确定谁是说真话的人,谁是撒谎者,并逐步解释你的推理(测试模型逻辑)
测试结果:

关于测试八Gemini 2.5和DeepseekV3的对比
操作过程:使用OpenRouter同时选择这两个模型并提问测试八的问题
操作结果:内容一致,Gemini2.5速度更快。