微信:adoresever
我的开源项目:
https://github.com/adoresever/DataGraphX_Learn
https://github.com/adoresever/Pretuning
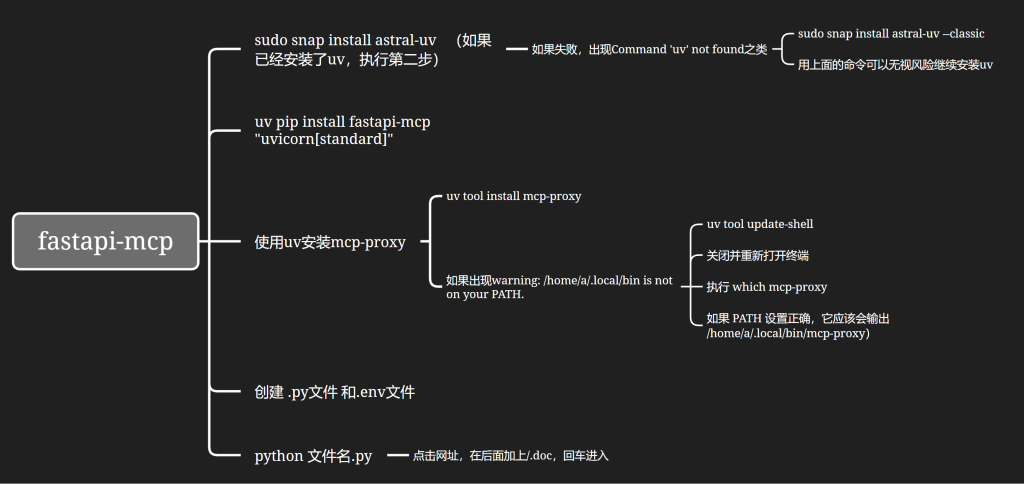
- fastapi-mcp安装部署
- sudo snap install astral-uv (如果已经安装了uv,执行第二步)
- 如果失败,出现Command ‘uv’ not found之类
- sudo snap install astral-uv –classic
- 用上面的命令可以无视风险继续安装uv
- 如果失败,出现Command ‘uv’ not found之类
- uv pip install fastapi-mcp “uvicorn[standard]”
- 使用uv安装mcp-proxy
- uv tool install mcp-proxy
- 如果出现warning: /home/a/.local/bin is not on your PATH.
- uv tool update-shell
- 关闭并重新打开终端
- 执行 which mcp-proxy
- 如果 PATH 设置正确,它应该会输出 /home/a/.local/bin/mcp-proxy)
- 创建 .py文件 和.env文件
- python 文件名.py
- 点击网址,在后面加上/.doc,回车进入
- sudo snap install astral-uv (如果已经安装了uv,执行第二步)
代码
import os
import httpx
from fastapi import FastAPI, HTTPException, Query
from fastapi_mcp import FastApiMCP
from pydantic import BaseModel, Field
from dotenv import load_dotenv
import logging
import json
# --- 配置与设置 ---
load_dotenv()
API_KEY = os.getenv("TAVILY_API_KEY")
if not API_KEY:
raise ValueError("在环境变量或 .env 文件中未找到 TAVILY_API_KEY")
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
TAVILY_API_URL = "https://api.tavily.com/search"
# --- Pydantic 模型 (目前保持不变) ---
class NewsResponse(BaseModel):
"""描述 Tavily 搜索工具返回的新闻摘要。"""
query: str = Field(..., description="用于搜索新闻的原始查询。")
news_summary: str = Field(..., description="由 Tavily AI 基于查询找到的近期新闻的更详细摘要,合并了多个来源。")
# --- FastAPI 应用 ---
app = FastAPI(
title="通过 MCP 使用 Tavily 搜索详细新闻", # 更新标题
description="使用 Tavily AI 搜索查找并合并近期新闻细节,基于查询,并通过 MCP 暴露。",
version="1.0.0",
)
# --- 新闻获取逻辑 (修改以获取更多细节) ---
async def fetch_detailed_news_from_tavily(news_query: str) -> str:
"""使用 Tavily AI 搜索新闻并合并结果以获取更多细节。"""
payload = json.dumps({
"api_key": API_KEY,
"query": news_query,
"search_depth": "advanced", # 使用高级搜索以获取可能更多的细节
"include_answer": False, # 如果你只想依赖结果内容,设为 False
"max_results": 7 # 增加考虑的结果数量
# "include_raw_content": True # 可选:可能获取更多原始内容,但需要仔细解析
})
headers = {'Content-Type': 'application/json'}
async with httpx.AsyncClient(timeout=30.0) as client: # 为高级搜索增加超时时间
response_data = None
try:
logger.info(f"正在向 Tavily AI 请求关于查询 '{news_query}' 的详细新闻摘要...")
response = await client.post(TAVILY_API_URL, headers=headers, content=payload)
response.raise_for_status()
response_data = response.json()
logger.debug(f"Tavily 对于查询 '{news_query}' 的原始响应: {response_data}")
# --- 重点在于合并结果 ---
combined_summary = ""
if response_data.get("results"):
summaries = []
for i, res in enumerate(response_data["results"]):
title = res.get('title', f"来源 {i+1}")
content = res.get('content', '').strip() # 获取内容并去除首尾空格
# url = res.get('url', '#') # 如果需要,可以包含 URL
if content: # 仅当有内容时才包含
#清晰地格式化每个结果
summaries.append(f"--- 结果 {i+1}: {title} ---\n{content}")
if summaries:
# 使用两个换行符连接所有摘要
combined_summary = "\n\n".join(summaries)
# 如果需要,可以限制总长度
# max_len = 2000 # 示例长度限制
# if len(combined_summary) > max_len:
# combined_summary = combined_summary[:max_len] + "..."
logger.info(f"已合并来自 Tavily 对于查询 '{news_query}' 的 {len(summaries)} 条结果。")
return combined_summary
else:
logger.warning(f"Tavily 对于查询 '{news_query}' 的结果没有可用的内容进行合并。")
# 如果根本没有找到可用的结果
logger.warning(f"Tavily 对于查询 '{news_query}' 没有返回可用的结果。")
raise HTTPException(status_code=404, detail=f"无法使用 Tavily AI 找到与查询 '{news_query}' 匹配的近期新闻细节。")
# --- 异常处理 (与天气示例大部分相同) ---
except httpx.HTTPStatusError as exc:
error_detail = "与 Tavily AI 服务通信时出错。"
try: error_body = exc.response.json(); error_detail = error_body.get("error", error_detail)
except ValueError: error_detail = exc.response.text or error_detail
logger.error(f"从 Tavily 获取查询 '{news_query}' 的新闻时发生 HTTP 错误: {exc.response.status_code} - 详情: {error_detail}")
if exc.response.status_code in [401, 403]: raise HTTPException(status_code=exc.response.status_code, detail=f"Tavily API 密钥错误: {error_detail}") from exc
raise HTTPException(status_code=exc.response.status_code, detail=error_detail) from exc
except httpx.RequestError as exc:
logger.error(f"从 Tavily 获取查询 '{news_query}' 的新闻时发生网络错误: {exc}")
raise HTTPException(status_code=503, detail="无法连接到 Tavily AI 服务。") from exc
except ValueError as exc:
logger.error(f"解码来自 Tavily 对查询 '{news_query}' 的 JSON 响应时出错: {exc}")
raise HTTPException(status_code=500, detail="从 Tavily AI 服务收到无效的数据格式。") from exc
except Exception as exc:
logger.exception(f"获取查询 '{news_query}' 的 Tavily 新闻时发生意外错误: {exc}")
raise HTTPException(status_code=500, detail="获取新闻摘要时发生意外的内部错误。") from exc
# --- FastAPI 端点 (调用新的获取函数) ---
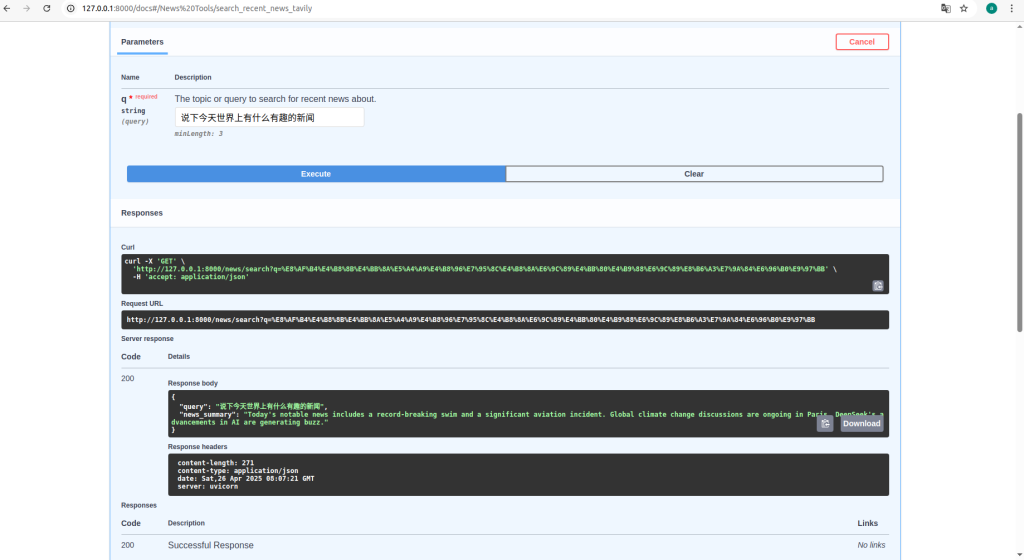
@app.get(
"/news/search",
response_model=NewsResponse,
operation_id="search_detailed_recent_news_tavily", # 更新 operation_id
summary="搜索详细近期新闻 (通过 Tavily AI)", # 更新摘要
tags=["News Tools", "Tavily AI"]
)
async def search_news(
q: str = Query(..., min_length=3, description="用于搜索近期新闻的主题或查询。")
):
"""
使用 Tavily AI 的高级搜索查找并合并来自近期新闻的细节,基于用户查询。
返回一个合并了多个来源的更长的文本摘要。
"""
logger.info(f"收到关于查询的详细新闻搜索请求: {q}")
# 调用修改后的获取函数
news_summary_text = await fetch_detailed_news_from_tavily(q)
response_data = NewsResponse(
query=q,
news_summary=news_summary_text
)
logger.info(f"已通过 Tavily 成功检索到查询 '{q}' 的详细新闻摘要。")
return response_data
# --- FastAPI-MCP 集成 ---
logger.info("正在初始化 FastAPI-MCP...")
mcp = FastApiMCP(app)
mcp.mount()
logger.info("FastAPI-MCP 服务器已挂载到 /mcp")
# --- 运行服务器 ---
if __name__ == "__main__":
import uvicorn
logger.info("正在启动用于 Tavily 详细新闻的 Uvicorn 服务器...")
uvicorn.run(
"news_mcp:app", # 确保文件名匹配
host="127.0.0.1",
port=8000, # 如果天气服务也在运行,可以更改端口,例如 8001
reload=True
)