可加V:adoresever
“””搜索智能体 – 使用 autogen_core 架构 (Powered by Qwen + 智谱 + 阿里通义)
【海报生成最终优化版:精确复现Web UI参数】
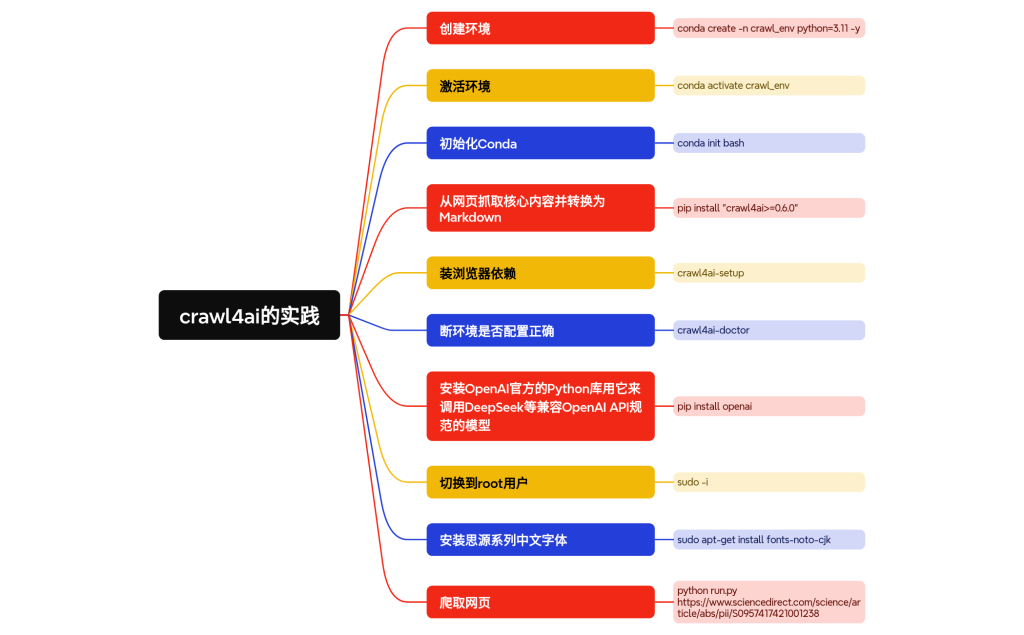
工作流程:
1. 用户输入 InitialQuestion
2. QueryGeneratorAgent 接收并生成 SearchQuery
3. SearcherAgent 使用智谱API获取 SearchResults
– 如果无结果,直接跳到步骤 8
4. SummarizerAgent 接收 SearchResults 并生成 FinalAnswer
– 生成答案后,智能判断答案是否有实质内容
– 如果无实质内容,直接跳到步骤 8
5. PosterDesignAgent 接收 FinalAnswer 并生成海报描述
6. Text2ImagePromptAgent 接收海报描述并优化为文生图提示词
7. ImageGeneratorAgent 接收优化后的提示词并调用通义万相API生成图片
8. ResultPrinterAgent 接收最终结果并打印给用户
“””
import os
import json
import requests
import time
import asyncio
from typing import List, Dict, Optional
from datetime import datetime
from asyncio import Event
from pathlib import Path
from http import HTTPStatus
import dashscope
from dashscope.api_entities.dashscope_response import ImageSynthesisResponse
from openai import OpenAI
from dotenv import load_dotenv
from pydantic import BaseModel
from autogen_core import (
DefaultTopicId,
MessageContext,
RoutedAgent,
AgentId,
SingleThreadedAgentRuntime,
default_subscription,
message_handler,
)
# — 配置与初始化 —
load_dotenv()
QWEN_API_KEY = os.getenv(“QWEN_API_KEY”)
ZHIPU_API_KEY = os.getenv(“ZHIPU_API_KEY”)
DASHSCOPE_API_KEY = os.getenv(“DASHSCOPE_API_KEY”)
if not QWEN_API_KEY:
raise ValueError(“请在 .env 文件中设置 QWEN_API_KEY”)
if not ZHIPU_API_KEY:
raise ValueError(“请在 .env 文件中设置 ZHIPU_API_KEY”)
if not DASHSCOPE_API_KEY:
raise ValueError(“请在 .env 文件中设置 DASHSCOPE_API_KEY (值为您的阿里云 AccessKey Secret)”)
qwen_client = OpenAI(
api_key=QWEN_API_KEY,
base_url=”https://dashscope.aliyuncs.com/compatible-mode/v1″,
)
# — 辅助函数 —
def log(agent_name: str, message: str, level: str = “INFO”):
“””打印日志信息”””
timestamp = datetime.now().strftime(“%H:%M:%S”)
color_map = {
“INFO”: “\033[94m”,
“SUCCESS”: “\033[92m”,
“ERROR”: “\033[91m”,
“WARNING”: “\033[93m”,
“ART”: “\033[95m”,
“ENDC”: “\033[0m”
}
color = color_map.get(level, “”)
end_color = color_map[“ENDC”] if color else “”
print(f”[{timestamp}] [{agent_name}] [{color}{level}{end_color}] {message}”)
def qwen_generate_smarter_query(question: str) -> str:
“””让 Qwen 基于用户问题生成更智能、更精准的搜索查询”””
prompt = “””你是一位顶级的AI信息分析师和搜索策略专家。你的任务是基于用户问题,生成一个在搜索引擎中最有可能找到高质量、相关信息的搜索查询。
【工作流程】
1. 分析意图:判断用户是想要定义、原因、影响、比较还是具体数据。
2. 提取要点:识别问题中的关键实体、概念及其关系。
3. 优化与扩展:修正拼写错误,替换或扩展关键词,确保覆盖主要表达方式。
4. 构建查询:生成**简洁、精确、8–15个词**的自然语言搜索语句(避免完整句子,用关键词组合)。
【语言规则】
– 如果问题涉及国际化主题(如科研、科技、医学、全球新闻),请输出**英文查询**。
– 如果问题与中国本地相关(如政策、历史、人物、地区事件),请输出**中文查询**。
– 始终保持查询语言和问题语境一致,避免混合语言。
【输出要求】
– 直接输出最终的查询语句,不要任何解释、前缀、编号或引号。
– 如不足8词,请补充同义词或相关关键词。
【示例】
用户问题:世界上最高的山是哪座?
最终查询:highest mountain in the world height Everest
用户问题:新能源车补贴政策对市场的影响?
最终查询:新能源汽车 补贴 政策 市场 影响 中国 2024
“””
try:
resp = qwen_client.chat.completions.create(
model=”qwen-plus”,
messages=[
{“role”: “system”, “content”: prompt},
{“role”: “user”, “content”: f”用户问题:{question}\n最终查询:”},
],
temperature=0.2,
max_tokens=100,
)
query = resp.choices[0].message.content.strip()
return query.strip(‘”\n ‘)
except Exception as e:
log(“QWEN_QUERY_HELPER”, f”生成智能查询失败: {e}”, “ERROR”)
return question
def zhipu_web_search(query: str, search_type: str = “search_pro”) -> List[Dict]:
“””调用智谱独立的搜索API”””
headers = {
“Authorization”: f”Bearer {ZHIPU_API_KEY}”,
“Content-Type”: “application/json”
}
url = “https://open.bigmodel.cn/api/paas/v4/web_search”
payload = {“search_query”: query, “search_engine”: search_type, “search_intent”: False}
try:
log(“ZHIPU_SEARCH”, f”正在使用 {search_type} 搜索: {query}”, “INFO”)
resp = requests.post(url, headers=headers, json=payload, timeout=30)
if resp.status_code == 200:
data = resp.json()
search_results = data.get(‘search_result’, [])
if search_results:
log(“ZHIPU_SEARCH”, f”成功获取 {len(search_results)} 条搜索结果”, “SUCCESS”)
return [{
“index”: i + 1,
“title”: item.get(“title”, “无标题”),
“url”: item.get(“link”, “”),
“content”: item.get(“content”, “无内容摘要”),
“source”: item.get(“refer”, “未知来源”),
“media_type”: item.get(“media”, “”)
} for i, item in enumerate(search_results)]
else:
log(“ZHIPU_SEARCH”, “搜索API返回空结果”, “WARNING”)
return []
else:
log(“ZHIPU_SEARCH”, f”请求失败,状态码: {resp.status_code}”, “ERROR”)
log(“ZHIPU_SEARCH”, f”响应内容: {resp.text[:500]}”, “ERROR”)
except Exception as e:
log(“ZHIPU_SEARCH”, f”未知错误: {e}”, “ERROR”)
return []
def zhipu_search_with_retry(query: str, max_retries: int = 2) -> List[Dict]:
“””带重试机制的智谱搜索”””
search_engines = [“search_pro”, “search_lite”]
for engine in search_engines:
for attempt in range(max_retries):
results = zhipu_web_search(query, engine)
if results: return results
if attempt < max_retries - 1:
log(“ZHIPU_SEARCH”, f”第 {attempt + 1} 次尝试无结果,重试中…”, “WARNING”)
time.sleep(1)
log(“ZHIPU_SEARCH”, “所有搜索尝试均失败”, “ERROR”)
return []
def format_search_results(results: List[Dict]) -> str:
“””格式化搜索结果用于总结”””
if not results: return “未找到相关搜索结果”
formatted = []
for r in results:
result_text = f”【结果 {r[‘index’]}】\n标题: {r[‘title’]}\n来源: {r[‘source’]}\n”
if r.get(‘url’): result_text += f”链接: {r[‘url’]}\n”
result_text += f”内容摘要: {r[‘content’]}\n”
formatted.append(result_text)
return “\n”.join(formatted)
def qwen_summarize(question: str, search_results: str) -> str:
“””让 Qwen 基于搜索结果生成结构化答案”””
prompt = “””你是一个专业、严谨、客观的分析助手。你的任务是基于下面提供的”网页搜索结果”,为用户的”原始问题”生成一个全面、深入且结构化的回答。
【核心原则】
1. 忠于原文:回答中的所有信息点必须直接来源于提供的搜索结果,禁止凭空编造。
2. 全面整合:综合多个来源,识别核心观点、关键数据和不同角度的看法。
3. 结构化表达:输出必须包含以下三个部分:
– **概要**:对整体问题的简要总结(2-3句话)。
– **详细分析**:按要点或子问题展开,使用列表或小标题组织;每个事实性陈述后必须标注来源编号(如:来源:结果1)。
– **结论**:总结主要发现,并明确指出哪些方面资料不足或存在分歧。
4. 引用来源:确保每个关键信息点后均有来源编号。
5. 信息不足:如果搜索结果无法完全回答问题,需明确指出缺失的部分,而不是泛泛地说”不足”。
【输出要求】
– 用简洁、专业的语言撰写,避免空话和套话。
– 确保回答逻辑清晰,可直接展示给用户。
“””
try:
resp = qwen_client.chat.completions.create(
model=”qwen-plus”,
messages=[
{“role”: “system”, “content”: prompt},
{“role”: “user”, “content”: f”原始问题:{question}\n\n网页搜索结果:\n{search_results}\n\n请基于以上搜索结果提供详细的答案。”},
],
temperature=0.3,
max_tokens=2500,
)
return resp.choices[0].message.content.strip()
except Exception as e:
log(“QWEN_SUMMARIZE”, f”生成答案失败: {e}”, “ERROR”)
return “抱歉,生成答案时遇到问题,请稍后再试。”
def is_answer_conclusive(answer: str) -> bool:
“””
使用 Qwen 判断一个答案是否是实质性的,还是仅仅表示”未找到信息”。
返回 True 表示答案是实质性的,False 表示是否定的/无信息的。
“””
prompt = “””你的任务是判断以下文本是否提供了实质性的信息。
请只回答 “YES” 或 “NO”。
– 如果文本**主要内容**是在解释一个概念、提供数据、分析原因或进行对比,即使它在结尾或部分内容中提到”某些信息未找到”或”仍需发展”,也应被视为提供了实质性信息。请回答 “YES”。
– 只有当文本**通篇**都在表达”未能找到相关信息”、”无法回答”、”搜索结果为空”等类似含义时,才应回答 “NO”。
简单来说,只要文本不仅仅是一句简单的”我找不到”,就回答 “YES”。
文本内容如下:
—
{text}
—
你的回答 (YES/NO):”””
try:
resp = qwen_client.chat.completions.create(
model=”qwen-plus”,
messages=[{“role”: “user”, “content”: prompt.format(text=answer)}],
temperature=0.0,
max_tokens=5,
)
decision = resp.choices[0].message.content.strip().upper()
log(“ANSWER_CHECKER”, f”判断答案有效性的结果: ‘{decision}'”, “INFO”)
return “YES” in decision
except Exception as e:
log(“ANSWER_CHECKER”, f”判断答案有效性时出错: {e}”, “ERROR”)
return True
def generate_poster_prompt_from_answer(final_answer: str, original_question: str) -> str:
“””
直接从最终答案生成海报提示词的一体化方法
“””
prompt = “””你是一位资深的信息设计师,擅长将复杂信息转化为视觉海报。
**任务**:基于下面的问答内容,设计一张信息海报的详细描述。
**用户问题**:{question}
**答案内容**:{answer}
**海报设计要求**:
1. **信息提取**:
– 从答案中提取1个核心观点作为主标题
– 选择3-5个关键信息点作为海报内容
– 保留重要的数字、名称、术语
2. **视觉设计规范**:
– 设计竖版海报(适合手机屏幕浏览)
– 标题醒目,占据上方1/3空间
– 中部展示核心信息(图表/图标/要点)
– 底部可包含补充信息或来源
3. **风格指导**:
– 根据内容选择合适风格(科技/商务/教育/新闻等)
– 配色方案要符合主题
– 包含适当的装饰元素增强视觉效果
4. **文字要求**:
– 所有文字必须用引号明确标出
– 中文内容确保表达准确
– 数据必须醒目展示
**输出示例**:
竖版新闻资讯海报,顶部超大标题”GPT-5即将发布”配红色警示效果,中间三个信息卡片分别展示”2025年Q2上线””性能提升10倍””支持视频生成”,卡片使用玻璃拟态效果,底部小字”来源:OpenAI官方”,背景使用浅灰渐变配几何图形装饰,整体现代简约风格
**现在生成海报描述**(100-150字):
“””
try:
# 截取答案的核心部分,避免太长
answer_summary = final_answer[:800] if len(final_answer) > 800 else final_answer
resp = qwen_client.chat.completions.create(
model=”qwen-plus”,
messages=[
{“role”: “user”, “content”: prompt.format(
question=original_question,
answer=answer_summary
)},
],
temperature=0.4,
max_tokens=500,
)
return resp.choices[0].message.content.strip()
except Exception as e:
log(“POSTER_PROMPT_DIRECT”, f”直接生成海报提示词失败: {e}”, “ERROR”)
return “信息展示海报设计”
def qwen_optimize_for_text2img(poster_description: str, original_question: str = None) -> str:
“””
将海报描述转换为优化的中文文生图提示词
专门针对通义万相等中文友好的模型优化
“””
prompt = “””你是一位专业的AI绘图提示词工程师,精通通义万相、文心一格等中文文生图模型。
你的任务是将海报描述转换为通义万相能够准确理解的【中文提示词】。
【输入信息】
海报描述:{poster_desc}
{context}
【转换要求】
1. **核心内容保留**(最重要):
– 保留所有文字内容,确保准确
– 保留关键数据、数字、百分比
– 品牌名、产品名、英文专有名词保持原样
2. **中文描述优化**:
– 使用中文描述场景和风格
– 质量描述:高质量、精细、专业设计、清晰
– 风格描述:现代风格、简约设计、商务风格、科技感(根据内容调整)
– 构图描述:居中构图、对称布局、三分法构图等
3. **提示词结构**:
– 主体在前:先描述是什么(海报、信息图、展板等)
– 内容在中:具体的文字、数据、图表
– 风格在后:视觉效果、色彩、氛围
– 用中文逗号(,)分隔不同要素
4. **通义万相特性优化**:
– 明确指出文字内容:”标题写着…”、”显示文字…”
– 强调文字清晰:”文字清晰可读”、”字体醒目”
– 避免过于复杂的场景描述
– 使用通义万相擅长的风格词:扁平化设计、矢量插画、渐变色彩等
【输出格式】
生成一个纯中文的优化提示词(100-150字),重要元素在前,装饰性描述在后。
【示例】
输入:竖版科技产品发布海报,顶部大字标题”DeepSeek V3.1 震撼发布”,中间展示架构图…
输出:专业科技产品发布海报设计,顶部大标题显示”DeepSeek V3.1 震撼发布”,中央展示UE8M架构图,性能提升图表显示”45%提升”,深蓝到紫色渐变背景,发光特效装饰,高质量信息图设计,现代商务风格,居中对称构图,文字清晰醒目
现在请优化:
“””
context = f”原始问题背景:{original_question}” if original_question else “”
try:
resp = qwen_client.chat.completions.create(
model=”qwen-plus”,
messages=[
{“role”: “user”, “content”: prompt.format(
poster_desc=poster_description,
context=context
)},
],
temperature=0.3,
max_tokens=400,
)
return resp.choices[0].message.content.strip()
except Exception as e:
log(“QWEN_T2I_OPTIMIZE”, f”优化文生图提示词失败: {e}”, “ERROR”)
return poster_description
# ==================== 代码修改区域 START ====================
def aliyun_text_to_image_enhanced(prompt: str, model_id: str = “wan2.2-t2i-flash”) -> Optional[str]:
“””
使用优化后的中文提示词生成图片
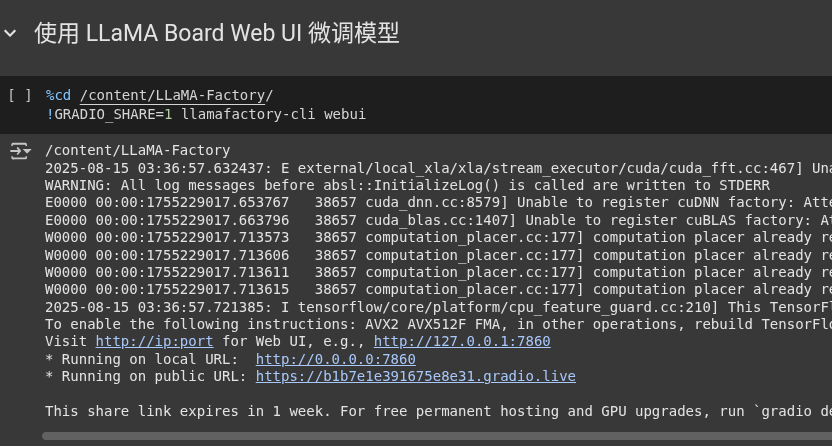
【最终修正版】根据Web UI截图精确复现参数
“””
dashscope.api_key = DASHSCOPE_API_KEY
output_dir = Path(“outputs”)
output_dir.mkdir(exist_ok=True)
try:
log(“ALIYUN_T2I”, f”正在使用模型 ‘{model_id}’ 生成图片…”, “ART”)
log(“ALIYUN_T2I”, f”中文提示词预览: {prompt[:150]}…”, “INFO”)
# 针对中文海报优化的负面提示词
negative_prompt = (
“乱码文字, 无法阅读的文本, 错误的文字, 丑陋的字体, 拼写错误, “
“低质量, 模糊, 扭曲, 丑陋, 多余的手指, “
“糟糕的构图, 混乱的布局, 业余设计, 元素重叠”
)
# 【最终修改】完全按照Web UI的参数进行配置
response: ImageSynthesisResponse = dashscope.ImageSynthesis.call(
model=model_id,
prompt=prompt,
negative_prompt=negative_prompt,
n=1,
# 关键点 1: 尺寸 (Size) – 完全匹配UI
size=’832*1088′,
# 关键点 2: 风格 (Style) – 模拟 “prompt_extend” 和提示词内容
style=’
# 关键点 3: 种子 (Seed) – 保证结果可复现
seed=1234,
)
if response.status_code == HTTPStatus.OK:
if response.output and response.output.results:
image_url = response.output.results[0].url
log(“ALIYUN_T2I”, “图片生成成功,正在下载…”, “SUCCESS”)
image_response = requests.get(image_url, timeout=30)
if image_response.status_code == 200:
timestamp = datetime.now().strftime(“%Y%m%d_%H%M%S”)
if “海报” in prompt:
filename = f”poster_{timestamp}.png”
elif “信息图” in prompt:
filename = f”infographic_{timestamp}.png”
else:
filename = f”generated_{timestamp}.png”
file_path = output_dir / filename
with open(file_path, ‘wb’) as f:
f.write(image_response.content)
log(“ALIYUN_T2I”, f”图片已保存至: {file_path}”, “SUCCESS”)
return str(file_path)
else:
log(“ALIYUN_T2I”, f”下载失败: {image_response.status_code}”, “ERROR”)
else:
log(“ALIYUN_T2I”, “API返回空结果”, “ERROR”)
else:
log(“ALIYUN_T2I”, f”API调用失败: {response.code} – {response.message}”, “ERROR”)
except Exception as e:
log(“ALIYUN_T2I”, f”生成图片时发生错误: {e}”, “ERROR”)
return None
# ==================== 代码修改区域 END ====================
# — 消息定义 —
class InitialQuestion(BaseModel):
content: str
start_time: float
completion_event: Event
class Config: arbitrary_types_allowed = True
class SearchQuery(BaseModel):
content: str
original_question: InitialQuestion
class SearchResults(BaseModel):
content: List[Dict]
original_question: InitialQuestion
search_query: str
class FinalAnswer(BaseModel):
content: str
original_question: InitialQuestion
class PosterDescription(BaseModel):
content: str
original_final_answer: FinalAnswer
class OptimizedPrompt(BaseModel):
content: str
original_final_answer: FinalAnswer
class FinalResultWithImage(BaseModel):
final_answer: FinalAnswer
image_prompt: str
image_path: Optional[str]
# — Agent 定义 —
@default_subscription
class QueryGeneratorAgent(RoutedAgent):
def __init__(self) -> None:
super().__init__(“An agent that generates a search query.”)
@message_handler
async def handle_initial_question(self, message: InitialQuestion, ctx: MessageContext) -> None:
log(self.id, “【步骤 1/7】收到初始问题,正在生成智能搜索查询…”)
query = qwen_generate_smarter_query(message.content)
log(self.id, f”生成查询: {query}”, “SUCCESS”)
await self.publish_message(
SearchQuery(content=query, original_question=message),
DefaultTopicId()
)
@default_subscription
class SearcherAgent(RoutedAgent):
def __init__(self) -> None:
super().__init__(“An agent that performs web searches.”)
@message_handler
async def handle_search_query(self, message: SearchQuery, ctx: MessageContext) -> None:
log(self.id, f”【步骤 2/7】收到查询 ‘{message.content}’, 正在执行搜索…”)
results = zhipu_search_with_retry(message.content, max_retries=2)
if results:
log(self.id, f”搜索完成,找到 {len(results)} 条结果。”, “SUCCESS”)
await self.publish_message(
SearchResults(
content=results,
original_question=message.original_question,
search_query=message.content
),
DefaultTopicId()
)
else:
log(self.id, “未能获取搜索结果,将直接结束流程。”, “WARNING”)
no_result_answer = FinalAnswer(
content=f”抱歉,未能找到关于 ‘{message.content}’ 的任何相关信息。”,
original_question=message.original_question
)
final_result = FinalResultWithImage(
final_answer=no_result_answer,
image_prompt=”由于未找到搜索结果,因此跳过了图片生成。”,
image_path=None
)
await self.publish_message(final_result, DefaultTopicId())
@default_subscription
class SummarizerAgent(RoutedAgent):
def __init__(self) -> None:
super().__init__(“An agent that summarizes search results.”)
@message_handler
async def handle_search_results(self, message: SearchResults, ctx: MessageContext) -> None:
log(self.id, “【步骤 3/7】收到搜索结果,正在生成最终答案…”)
formatted_results = format_search_results(message.content)
final_answer_content = qwen_summarize(message.original_question.content, formatted_results)
log(self.id, “答案生成完成。”, “SUCCESS”)
log(self.id, “正在智能分析答案的有效性…”, “INFO”)
if is_answer_conclusive(final_answer_content):
log(self.id, “答案有效,流程继续…”, “SUCCESS”)
await self.publish_message(
FinalAnswer(
content=final_answer_content,
original_question=message.original_question
),
DefaultTopicId()
)
else:
log(self.id, “答案无效 (未找到实质性信息),将直接结束流程。”, “WARNING”)
final_answer_obj = FinalAnswer(
content=final_answer_content,
original_question=message.original_question
)
final_result = FinalResultWithImage(
final_answer=final_answer_obj,
image_prompt=”由于搜索结果未能提供实质性答案,因此跳过了图片生成。”,
image_path=None
)
await self.publish_message(final_result, DefaultTopicId())
@default_subscription
class PosterDesignAgent(RoutedAgent):
“””专门负责海报设计方案生成的Agent”””
def __init__(self) -> None:
super().__init__(“An agent that generates poster design descriptions.”)
@message_handler
async def handle_final_answer(self, message: FinalAnswer, ctx: MessageContext) -> None:
log(self.id, “【步骤 4/7】收到最终答案,正在生成海报设计方案…”, “ART”)
# 直接从答案生成海报描述
poster_description = generate_poster_prompt_from_answer(
message.content,
message.original_question.content
)
log(self.id, f”海报设计方案生成完成”, “SUCCESS”)
log(self.id, f”方案预览: {poster_description[:100]}…”, “INFO”)
# 发送给下一个Agent
await self.publish_message(
PosterDescription(
content=poster_description,
original_final_answer=message
),
DefaultTopicId()
)
@default_subscription
class Text2ImagePromptAgent(RoutedAgent):
“””专门负责将海报描述优化为文生图提示词的Agent”””
def __init__(self) -> None:
super().__init__(“An agent that optimizes prompts for text-to-image generation.”)
@message_handler
async def handle_poster_description(self, message: PosterDescription, ctx: MessageContext) -> None:
log(self.id, “【步骤 5/7】收到海报描述,正在优化为文生图提示词…”, “ART”)
poster_description = message.content
original_question = message.original_final_answer.original_question.content
# 优化为文生图提示词
optimized_prompt = qwen_optimize_for_text2img(
poster_description,
original_question
)
log(self.id, f”文生图提示词优化完成”, “SUCCESS”)
log(self.id, f”优化后: {optimized_prompt[:100]}…”, “INFO”)
# 发送给图片生成Agent
await self.publish_message(
OptimizedPrompt(
content=optimized_prompt,
original_final_answer=message.original_final_answer
),
DefaultTopicId()
)
@default_subscription
class ImageGeneratorAgent(RoutedAgent):
“””负责调用通义万相生成图片的Agent”””
def __init__(self) -> None:
super().__init__(“An agent that generates images.”)
@message_handler
async def handle_optimized_prompt(self, message: OptimizedPrompt, ctx: MessageContext) -> None:
log(self.id, “【步骤 6/7】收到优化后的提示词,正在调用通义万相生成图片…”)
# 生成图片
image_path = aliyun_text_to_image_enhanced(message.content)
if image_path:
log(self.id, “图片生成成功!”, “SUCCESS”)
else:
log(self.id, “图片生成失败。”, “ERROR”)
# 发送最终结果
await self.publish_message(
FinalResultWithImage(
final_answer=message.original_final_answer,
image_prompt=message.content,
image_path=image_path
),
DefaultTopicId()
)
@default_subscription
class ResultPrinterAgent(RoutedAgent):
“””负责打印最终结果的Agent”””
def __init__(self) -> None:
super().__init__(“An agent that prints the final result.”)
@message_handler
async def handle_final_result_with_image(self, message: FinalResultWithImage, ctx: MessageContext) -> None:
log(self.id, “【步骤 7/7】收到最终结果,准备输出。”)
final_answer = message.final_answer
elapsed_time = time.time() – final_answer.original_question.start_time
# 打印结果
print(“\n” + “=”*60 + “\n📊 最终答案\n” + “=”*60)
print(final_answer.content)
print(“\n” + “=”*60 + “\n🎨 文生图提示词\n” + “=”*60)
print(message.image_prompt)
print(“\n” + “=”*60 + “\n🖼️ 生成的图片\n” + “=”*60)
if message.image_path:
print(f”✅ 图片已成功保存至: {message.image_path}”)
print(f”📁 请在 outputs 文件夹中查看生成的海报”)
elif “跳过了图片生成” in message.image_prompt:
print(f”⚠️ {message.image_prompt}”)
else:
print(“❌ 图片生成失败,请检查日志获取详细信息。”)
print(“\n” + “=”*60 + f”\n⏱️ 总耗时: {elapsed_time:.2f} 秒\n” + “=”*60)
# 设置完成事件
final_answer.original_question.completion_event.set()
# — 主程序 —
async def main():
print(“\n” + “🚀 ” + “=”*56 + ” 🚀”)
print(” 欢迎使用智能搜索与海报生成系统 (V7.1)”)
print(” Powered by autogen_core + Qwen + 智谱 + 阿里通义”)
print(“🚀 ” + “=”*56 + ” 🚀”)
print(“\n功能特色:”)
print(” 📝 智能搜索:基于问题生成最优搜索策略”)
print(” 🔍 信息整合:从多源数据中提取核心信息”)
print(” 🎨 海报设计:自动生成专业的信息海报”)
print(” 🖼️ AI绘图:使用通义万相生成高质量图片”)
print(“\n输入 ‘quit’ 或 ‘exit’ 退出程序\n” + “-” * 64)
# 创建运行时
runtime = SingleThreadedAgentRuntime()
# 注册所有Agent
await QueryGeneratorAgent.register(
runtime, “query_generator”,
lambda: QueryGeneratorAgent()
)
await SearcherAgent.register(
runtime, “searcher”,
lambda: SearcherAgent()
)
await SummarizerAgent.register(
runtime, “summarizer”,
lambda: SummarizerAgent()
)
await PosterDesignAgent.register(
runtime, “poster_designer”,
lambda: PosterDesignAgent()
)
await Text2ImagePromptAgent.register(
runtime, “text2image_optimizer”,
lambda: Text2ImagePromptAgent()
)
await ImageGeneratorAgent.register(
runtime, “image_generator”,
lambda: ImageGeneratorAgent()
)
await ResultPrinterAgent.register(
runtime, “result_printer”,
lambda: ResultPrinterAgent()
)
# 启动运行时
runtime.start()
try:
while True:
# 创建完成事件
completion_event = asyncio.Event()
# 获取用户输入
question = input(“\n💭 请输入您的问题: “).strip()
if not question:
continue
if question.lower() in [‘quit’, ‘exit’, ‘q’]:
print(“\n👋 感谢使用,再见!”)
break
# 显示处理开始
print(“\n” + “=”*64)
print(“🔍 智能搜索与海报生成系统”)
print(“=”*64)
print(f”📝 您的问题: {question}\n”)
# 发送初始消息
await runtime.send_message(
InitialQuestion(
content=question,
start_time=time.time(),
completion_event=completion_event
),
AgentId(“query_generator”, “default”)
)
# 等待处理完成
await completion_event.wait()
finally:
log(“MAIN”, “正在停止运行时…”, “INFO”)
await runtime.stop()
log(“MAIN”, “系统已安全关闭”, “SUCCESS”)
if __name__ == “__main__”:
try:
# 运行主程序
asyncio.run(main())
except KeyboardInterrupt:
print(“\n\n👋 程序已中断,再见!”)
except Exception as e:
print(f”\n❌ 程序发生错误: {e}”)
import traceback
traceback.print_exc()