整体流程:
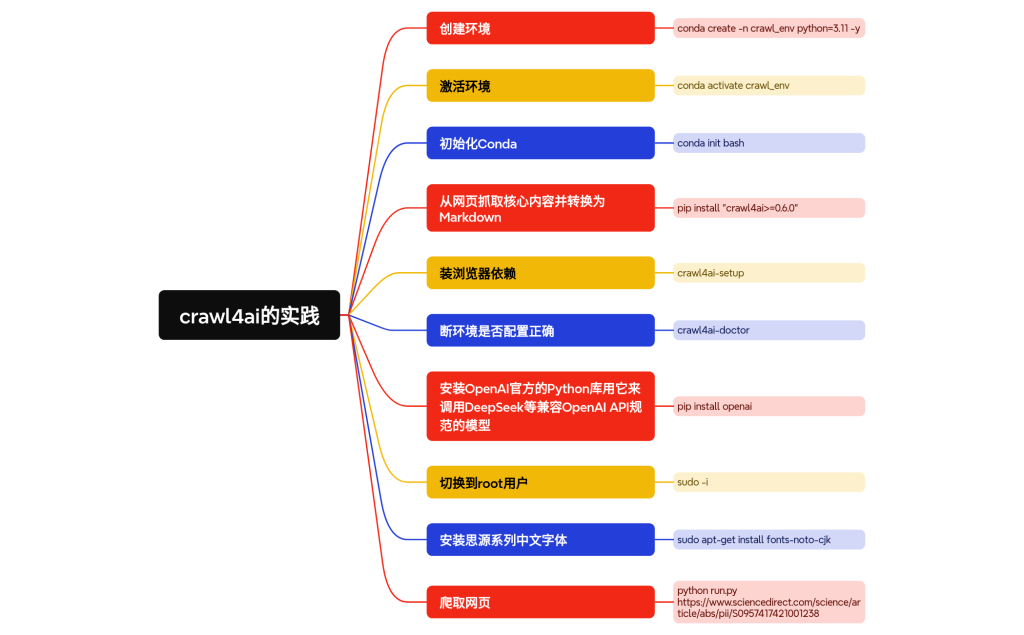
创建环境: conda create -n crawl_env python=3.11 -y
激活环境: conda activate crawl_env
初始化Conda:conda init bash
从网页抓取核心内容并转换为Markdown:pip install “crawl4ai>=0.6.0”
setup 用于安装浏览器依赖,doctor 用于诊断环境是否配置正确:crawl4ai-setup 和 crawl4ai-doctor
安装OpenAI官方的Python库用它来调用DeepSeek等兼容OpenAI API规范的模型:pip install openai
切换到root用户: sudo -i
安装思源系列中文字体:sudo apt-get install fonts-noto-cjk
目录结构:
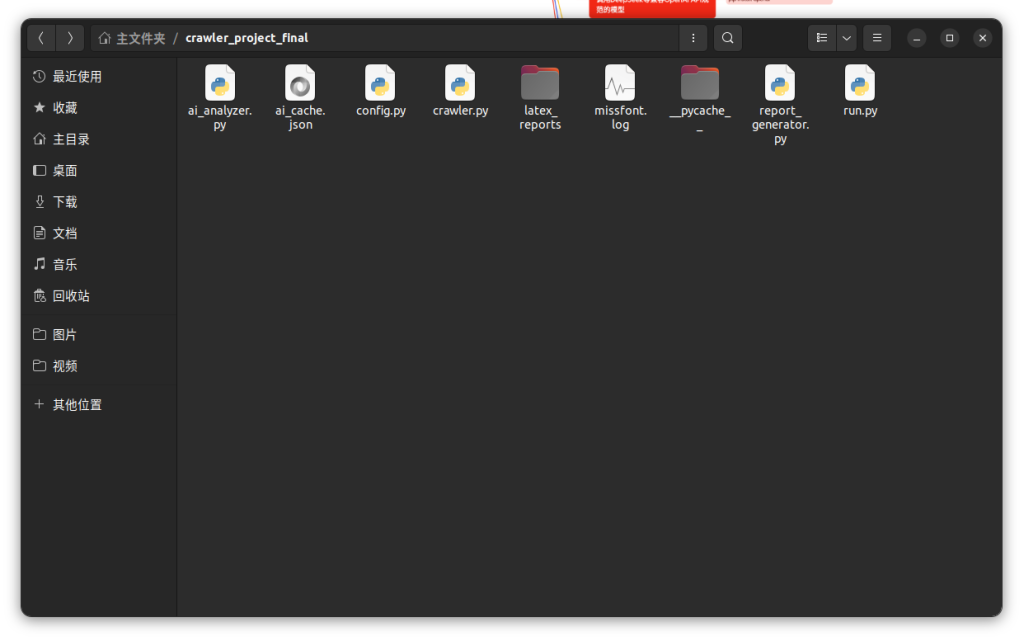
源码:
# ai_analyzer.py (修正版,增强章节定位能力)
# 负责与DeepSeek API交互,进行多任务分析
import asyncio
import re
import json
import os
from openai import AsyncOpenAI
from config import DEEPSEEK_API_KEY, DEEPSEEK_BASE_URL, DEFAULT_MODEL, CACHE_FILE
client = AsyncOpenAI(api_key=DEEPSEEK_API_KEY, base_url=DEEPSEEK_BASE_URL)
def _load_cache() -> dict:
# ... (这部分函数保持不变) ...
if os.path.exists(CACHE_FILE):
with open(CACHE_FILE, 'r', encoding='utf-8') as f:
try:
return json.load(f)
except json.JSONDecodeError:
return {}
return {}
def _save_cache(cache_data: dict):
# ... (这部分函数保持不变) ...
with open(CACHE_FILE, 'w', encoding='utf-8') as f:
json.dump(cache_data, f, ensure_ascii=False, indent=4)
async def _call_ai(system_prompt: str, user_content: str, model: str) -> str | None:
# ... (这部分函数保持不变) ...
try:
completion = await client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_content}
],
stream=False
)
return completion.choices[0].message.content
except Exception as e:
print(f"❌ 调用AI时发生错误: {e}")
return None
async def analyze_content(full_markdown: str, url: str, model: str = DEFAULT_MODEL) -> dict | None:
cache = _load_cache()
cache_key = url
if cache_key in cache and all(k in cache[cache_key] for k in ["abstract_translation", "main_body_summary", "conclusion_summary"]):
print("✅ 从本地缓存中加载AI分析结果!")
return cache[cache_key]
print(f"➡️ [步骤 2/4] 本地无缓存,正在连接AI进行分析 (模型: {model})...")
prompts = {
"abstract": "You are a professional academic translator. Your task is to accurately translate the following research paper abstract into simplified Chinese.",
"main_body": "You are an expert academic analyst. Summarize the core contributions, methods, and key findings from the main body of the following article in about 300-500 words. Present your summary in a structured, easy-to-read format in simplified Chinese.",
"conclusion": "You are an expert academic analyst. Your task is to summarize the conclusion section of the following article, highlighting the main takeaways and future work mentioned. Provide the summary in simplified Chinese."
}
abstract_regex = r'(?i)(?:#+\s*|\n)\s*(?:\d*\.?\s*)?Abstract\n(.*?)(?=\n#+\s|\n\d*\.?\s*Introduction)'
conclusion_regex = r'(?i)(?:#+\s*|\n)\s*(?:\d*\.?\s*)?Conclusion(?:s)?\n(.*?)(?=\n#+\s|\n\d*\.?\s*(?:References|Acknowledgements|Appendix))'
abstract_content_match = re.search(abstract_regex, full_markdown, re.DOTALL)
conclusion_content_match = re.search(conclusion_regex, full_markdown, re.DOTALL)
# 提取内容,如果找不到匹配项则提供明确提示
abstract_text = abstract_content_match.group(1).strip() if abstract_content_match else "Abstract not found in the document."
conclusion_text = conclusion_content_match.group(1).strip() if conclusion_content_match else "Conclusion not found in the document."
# 主体内容逻辑保持不变
main_body_content = full_markdown
if abstract_content_match and conclusion_content_match:
main_body_start = abstract_content_match.end()
main_body_end = conclusion_content_match.start()
main_body_content = full_markdown[main_body_start:main_body_end]
tasks = {
"abstract_translation": _call_ai(prompts["abstract"], abstract_text, model),
"main_body_summary": _call_ai(prompts["main_body"], main_body_content, model),
"conclusion_summary": _call_ai(prompts["conclusion"], conclusion_text, model),
}
results = await asyncio.gather(*tasks.values())
summaries = dict(zip(tasks.keys(), results))
if not all(summaries.values()):
print("❌ AI总结失败,部分内容未能生成。")
return None
print("✅ AI分析完成!正在将结果存入本地缓存...")
cache[cache_key] = summaries
_save_cache(cache)
return summaries修改你需要的模型:
# config.py
# 存放所有配置信息
import os
# ==============================================================================
# API与模型配置
# ==============================================================================
# 您的API密钥。
DEEPSEEK_API_KEY = " "
# DeepSeek的API服务器地址
DEEPSEEK_BASE_URL = "https://api.deepseek.com/v1"
# 要使用的AI模型名称
DEFAULT_MODEL = "deepseek-chat"
# ==============================================================================
# 输出配置
# ==============================================================================
# 生成的报告存放的文件夹名称
OUTPUT_DIR = "latex_reports"
# ==============================================================================
# 缓存配置
# ==============================================================================
# AI分析结果的缓存文件
CACHE_FILE = "ai_cache.json"# crawler.py
# 负责爬取网页内容
import re
from crawl4ai import AsyncWebCrawler
async def fetch_article_data(url: str) -> tuple[str | None, str | None]:
"""
爬取指定URL的网页,提取Markdown内容和标题。
返回: (markdown_content, title) 或 (None, None)
"""
print(f"➡️ [步骤 1/4] 正在爬取文献内容: {url}")
crawler = AsyncWebCrawler()
try:
result = await crawler.arun(url=url)
if not result or not result.markdown:
print(f"❌ 爬取失败: 未能从 {url} 提取到有效内容。")
return None, None
# 尝试从Markdown中提取第一个一级标题
title_match = re.search(r"^#\s+(.*)", result.markdown, re.MULTILINE)
title = title_match.group(1).strip() if title_match else "Untitled Document"
print("✅ 内容爬取成功!")
return result.markdown, title
except Exception as e:
print(f"❌ 爬取时发生错误: {e}")
return None, None# report_generator.py
# 负责生成LaTeX源码并编译成PDF
import os
import re
import subprocess
from datetime import datetime
from config import OUTPUT_DIR
def _latex_escape(text: str) -> str:
"""对文本进行转义以安全插入LaTeX。"""
replacements = {
'&': r'\&', '%': r'\%', '$': r'\$', '#': r'\#', '_': r'\_',
'{': r'\{', '}': r'\}', '~': r'\textasciitilde{}',
'^': r'\textasciicircum{}', '\\': r'\textbackslash{}',
}
return re.sub(r'[&%$#_{}\\~^]', lambda m: replacements[m.group(0)], text)
def _create_latex_source(data: dict) -> str:
"""根据数据生成LaTeX源文件内容。"""
title_escaped = _latex_escape(data['title'])
url_escaped = _latex_escape(data['url'])
abstract_escaped = _latex_escape(data.get('abstract_translation', ''))
main_body_escaped = _latex_escape(data.get('main_body_summary', ''))
conclusion_escaped = _latex_escape(data.get('conclusion_summary', ''))
latex_template = rf"""
\documentclass[12pt, a4paper]{{article}}
\usepackage{{ctex}}
\usepackage[top=2.5cm, bottom=2.5cm, left=2.5cm, right=2.5cm]{{geometry}}
\usepackage{{fancyhdr}}
\usepackage{{hyperref}}
\usepackage{{titling}}
\setmainfont{{Times New Roman}}
\pagestyle{{fancy}}
\fancyhf{{}}
\fancyhead[C]{{{title_escaped}}}
\fancyfoot[C]{{\thepage}}
\renewcommand{{\headrulewidth}}{{0.4pt}}
\renewcommand{{\footrulewidth}}{{0.4pt}}
\pretitle{{\begin{{center}}\LARGE\bfseries}}\posttitle{{\end{{center}}}}
\preauthor{{\begin{{center}}\large}}\postauthor{{\end{{center}}}}
\predate{{\begin{{center}}\large}}\postdate{{\end{{center}}}}
\title{{{title_escaped}}}
\author{{文献来源: \href{{{url_escaped}}}{{{url_escaped}}}}}
\date{{AI总结报告生成于: {data['date']}}}
\begin{{document}}
\maketitle
\thispagestyle{{fancy}}
\section*{{摘要翻译}}
{abstract_escaped}
\section*{{核心内容总结}}
{main_body_escaped}
\section*{{结论总结}}
{conclusion_escaped}
\end{{document}}
"""
return latex_template
def generate_pdf_report(report_data: dict):
print("➡️ [步骤 3/4] 正在生成LaTeX报告源文件...")
tex_source = _create_latex_source(report_data)
print("✅ LaTeX源文件生成完毕!")
print("➡️ [步骤 4/4] 正在编译PDF报告...")
os.makedirs(OUTPUT_DIR, exist_ok=True)
title = report_data.get('title', 'report')
filename_base = re.sub(r'[\\/*?:"<>|]', "", title).replace(" ", "_")[:50]
tex_filepath = os.path.join(OUTPUT_DIR, f"{filename_base}.tex")
with open(tex_filepath, 'w', encoding='utf-8') as f:
f.write(tex_source)
command = ['xelatex', '-interaction=nonstopmode', f'-output-directory={OUTPUT_DIR}', tex_filepath]
for i in range(2):
print(f" ... LaTeX编译中 (第 {i+1}/2 轮)")
result = subprocess.run(command, capture_output=True, text=True, encoding='utf-8')
if result.returncode != 0:
log_path = os.path.join(OUTPUT_DIR, f'{filename_base}.log')
print(f"❌ PDF编译失败!请查看日志: {log_path}")
print("-" * 20 + " LaTeX 错误日志 " + "-" * 20)
if os.path.exists(log_path):
with open(log_path, 'r', encoding='utf-8') as log_file:
print("".join(log_file.readlines()[-30:]))
print("-" * 55)
return
for ext in ['.aux', '.log', '.out', '.tex']:
try:
os.remove(os.path.join(OUTPUT_DIR, f"{filename_base}{ext}"))
except OSError:
pass
pdf_filepath = os.path.join(OUTPUT_DIR, f"{filename_base}.pdf")
print(f"🎉 报告生成成功!文件已保存至: {os.path.abspath(pdf_filepath)}")# run.py (带缓存功能)
# 主程序入口,负责调度所有模块
import asyncio
import sys
import argparse
import subprocess
import os
import json
from datetime import datetime
import config
from crawler import fetch_article_data
from ai_analyzer import analyze_content
from report_generator import generate_pdf_report
def check_dependencies():
"""检查必要的外部依赖(API密钥和LaTeX)。"""
if not config.DEEPSEEK_API_KEY:
print("❌ 错误: API密钥未在 config.py 中配置!")
sys.exit(1)
try:
subprocess.run(['xelatex', '-version'], check=True, capture_output=True)
except (subprocess.CalledProcessError, FileNotFoundError):
print("❌ 错误: 系统中未找到 'xelatex' 命令。请先安装LaTeX发行版。")
sys.exit(1)
async def main():
"""主执行流程"""
parser = argparse.ArgumentParser(description="学术文献AI总结报告生成器 V2.1 (带缓存)")
parser.add_argument('url', help="要处理的学术文献URL。")
parser.add_argument('--model', default=config.DEFAULT_MODEL, help=f"使用的DeepSeek模型 (默认: {config.DEFAULT_MODEL})。")
parser.add_argument('--force-reanalyze', action='store_true', help="强制重新进行AI分析,忽略此URL的现有缓存。")
args = parser.parse_args()
# 如果用户选择强制刷新,我们先从缓存中删除该URL的记录
if args.force_reanalyze and os.path.exists(config.CACHE_FILE):
print("🌀 用户选择强制重新分析,将更新此URL的缓存。")
try:
with open(config.CACHE_FILE, 'r', encoding='utf-8') as f:
cache = json.load(f)
if args.url in cache:
del cache[args.url]
with open(config.CACHE_FILE, 'w', encoding='utf-8') as f:
json.dump(cache, f, ensure_ascii=False, indent=4)
print(f" 已从缓存中移除URL: {args.url}")
except (json.JSONDecodeError, FileNotFoundError):
pass # 如果缓存文件有问题,忽略即可
# 1. 爬取
markdown, title = await fetch_article_data(args.url)
if not markdown:
return
# 2. AI分析
summaries = await analyze_content(markdown, args.url, args.model)
if not summaries:
return
# 3. 整合数据并生成报告
report_data = {
"title": title,
"url": args.url,
"date": datetime.now().strftime('%Y年%m月%d日'),
**summaries
}
generate_pdf_report(report_data)
if __name__ == "__main__":
print("--- 启动报告生成器 (带缓存功能) ---")
check_dependencies()
asyncio.run(main())
print("--- 报告生成器运行完毕 ---")爬取生成PDF:在latex_reports文件夹下
